참고: https://huggingface.co/docs/transformers/index
어쨌건 저쨌건 지금 가장 간편하게 머신러닝을 학습할 수 있는 Transformers
Huggingface의 튜토리얼을 먼저 따라해보자
챕터 1강은 Transformers가 뭔지, 어떤 모델인지, 간단하게 알아보기
파이프라인(pipeline() 함수: 전처리 & 후처리 모델과 연결)


- 말 그대로 파이프라인, 특정 모델과 동작에 필요한 전&후처리 단계를 연결해, 빠르고 편하게 이해할 수 있는 답변 얻기
- sentiment analysis task로 pipeline 객체를 만들고, classifier에 입력했더니 자동으로 모델 가져와서 태스크 수행하였음
* 파이프라인에 텍스트 입력시 preprocessing -> 모델에 텍스트 전달 -> postprocessing 자동으로 수행됨.
현재 가능한 파이프라인들
- feature-extraction : 특징 추출 (텍스트에 대한 벡터 표현 추출)
- fill-mask : 마스크(공백) 채우기
- Named Entity Recognition(NER) : 개체명 인식
- 입력 텍스트에서 어느 부분이 개체명(사람/위치/조직 등)인지 식별하기.
- question-answering : 질의 응답
- 주어진 context에서 정보를 추출해 작동 (응답의 새로운 생성은 X)
- sentiment-analysis : 감정 분석
- summarization : 요약
- text-generation : 텍스트 생성
- translation : 번역
- zero-shot-classification: 레이블이 지정되지 않은 텍스트 분류하기
- 해당 분류에 사용할 레이블을 마음대로 지정 가능 -> 완전히 새로운 레이블로 분류해도 fine-tuning 필요없음.


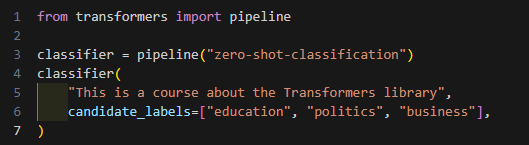
등 기본적인 태스크의 빠른 수행이 가능함.
Hub의 모델 사용하기 (model parameter로 load)

Transformer Models
- 2017년 Transformer Architecture (Attention is all you need) 최초 발표 이후 추가된 몇 가지 모델들
- GPT-계열 (Auto-regressive Transformer model)
- BERT-계열 (Auto-encoding Transformer model)
- BART/T5-계열 (Sequence-to-sequence Transformer model)
모든 모델들은 언어모델(Language Model): self-supervised learning을 이용해 원시 텍스트를 학습하였음.
- self-supervised learning(자가 지도 학습): 학습의 목적이 모델 입력으로부터 자동으로 계산되는 방식. 사람이 데이터에 레이블을 달지 않아도 학습이 가능
그런데, 이 때 실생활 문제 (원하는 문제)를 풀기 위해서, 전이학습(transfer learning) 과정 거쳐야 함 ->
- supervised learning(사람이 데이터에 레이블 추가) 방법으로 fine-tuning
학습방법
사전학습 (pretraining)
모델 처음부터 학습하는 방법. 모델 가중치(weight)를 랜덤하게 초기화, 사전 지식(prior knowledge)없이 학습을 시작.
미세조정 (fine-tuning)
모델이 모두 사전 학습을 마친 이후에 하는 학습. pretrained model + 특정 task에 맞는 dataset을 이용해 추가 학습을 수행하는 것.
* 파인튜닝의 이점:
- 이미 학습된 사전 지식이 있으므로, 유사한 corpus 사용 시 기존지식 활용 가능.
- pretraining보다 훨씬 작은 corpus 필요로 함.
e.g. 영어로 사전 학습된 모델 -> arXiv 코퍼스로 미세조정해 과학/연구기반 모델 제작 가능.
사전 학습 과정에서 얻은 지식이 “전이”되었다고 하여 전이 학습(transfer learning)이라 부름
* transfer learning: 사전 학습된 모델의 가중치로 새로운 모델을 초기화할 때, 사전학습된 모델의 지식이 전달되는 것.
Transformer architecture
: 어떤 문제를 풀고 싶냐에 따라서, 전체 모델 구조를 사용하거나 / 인코더 디코더만 사용할 수 있음!

인코더(Encoder)
encodes text into numerical representations (bi-directional & self-attentention)
- 입력에 대한 표현(representation), 특성(feature)을 도출.
- 입력에 대한 표현 형태가 최적화됨
각 단계에서 초기/원본 입력 문장(initial sentence)의 모든 단어에 엑세스할 수 있음 (auto-encoding model)
일반적으로 초기 문장을 손상 후 (masking 등), 원래 문장으로 복원하며 사전학습
디코더(Decoder)
decodes the representations from the encoder (uni-directional, auto-regressive, masked self-attention)
- 인코더의 표현(representation), 특성(feature)을 다른 입력과 함께 사용해 target sequence를 생성.
- 출력 생성(generating output)에 최적화됨
각 단계에서 주어진 단어에 대해, attention layer가 현재 처리 단어 앞쪽에만 엑세스 (auto-regressive model)
일반적으로 문장의 다음 단어 예측을 수행하며 사전학습
- Encoder-only model: Sentence Classification, NER과 같이 입력에 대한 분석/이해를 요구하는 작업에 특화
- Decoder-only model: 텍스트 생성과 같이 생성 관련 작업에 특화
- Encoder-Decoder (Seq-to-Seq) 모델: 번역, 요약, 생성형 질의응답과 같이 주어진 입력 + 새로운 문장 생성 작업에 적합
| Model | Examples | Tasks |
| Encoder | ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa | 문장 분류, 개체명 인식, 추출 질의응답 |
| Decoder | CTRL, GPT, GPT-2, Transformer XL | 텍스트 생성(prompt) |
| Seq-to-seq | BART, T5, Marian, mBART | 요약, 번역, 생성 질의응답 |
Attention layer
한줄요약: Attention layer가 각 단어의 표현을 처리할 때, 문장의 특정 단어에 attention(주의)을 기울이고 나머지는 거의 무시하도록 알려준다
단어의 의미가 context에 의해 영향을 받기 때문에!

- 어텐션 마스크(attention mask): 모델이 몇몇 특수 단어들에만 어텐션을 주는 것을 방지
- e.g. 문장 batching에 사용하는 padding word에 사용
Architectures vs. Checkpionts
- Architecture: 모델의 뼈대(skeleton) (모델 내부의 각 레이어, 각 연산 등을 정의함)
- Checkpoints: 해당 아키텍처에 로드(적용)될 가중치들
e.g.
BERT: architecture,
bert-base-cased (구글에서 학습한 가중치 셋): checkpoint
- Model: 아키텍처/체크포인트보다는 덜 명확한 단어(umbrella term) - 두 가지 모두를 의미할 수 있음.
Limitations
아무리 중립적인 데이터를 사용해 사전학습했더라도, 편향성bias을 갖게될 수 있음.
모델이 편향성을 갖게 되는 원인들...
- 전이 학습 시 사용되는 사전 학습 모델의 편향성이 미세 조정된 모델로도 전달됩니다.
- 모델 학습에 사용된 데이터가 편향됨
- 모델이 최적화한 메트릭(metric)이 편향 불분명한 원인 중 하나입니다. 모델은 어떤 메트릭을 고르든 아무 생각 없이 그에 맞춰 최적화를 합니다.
'AI-자연어처리' 카테고리의 다른 글
| [LlamaIndex] 튜토리얼 (0) | 2024.05.31 |
|---|---|
| [Langchain] 써보기 (0) | 2024.05.17 |
| [Huggingface Tutorial/Ch5] Dataset Library로 huggingface에 데이터셋 다루기 1 (1) | 2024.03.29 |
| [Huggingface Tutorial/Ch3] 사전학습 모델 파인튜닝하기 (0) | 2024.03.29 |
| [Huggingface Tutorial/Ch2] Transformers 라이브러리 사용하기 (0) | 2024.03.26 |